
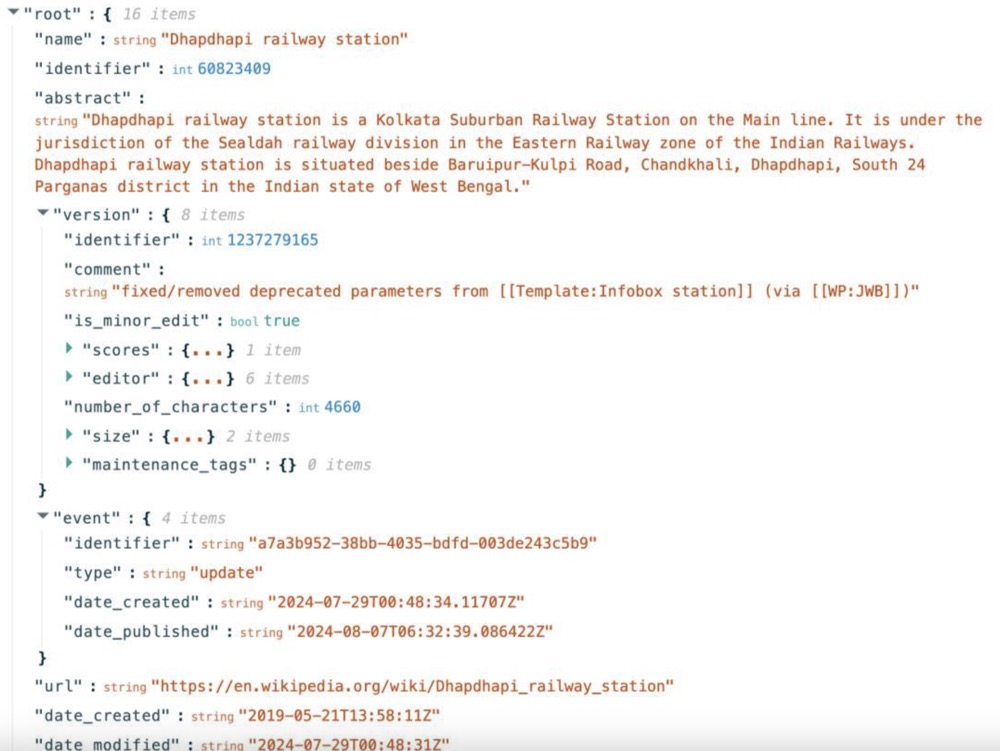
AI 爬虫与维基百科的“投降”

AI 爬虫与维基百科的“投降”
0x3ff18a2025 年初,互联网世界见证了一场颇具戏剧性的“投降”。全球最大的在线百科全书维基百科向 AI 爬虫举起了白旗。运营维基百科的维基媒体基金会宣布,将英语和法语版本的维基百科内容托管在谷歌旗下的数据科学社区平台 Kaggle 上,专门为 AI 公司提 AI 能看懂的供结构化数据包。这一决定看似突然,实则是长达将近一年半的技术博弈的必然结果。
自 2024 年 1 月以来,维基共享资源(Wikimedia Commons)上 1.44 亿个多媒体文件的网络带宽使用量激增 50%,而这些流量几乎全部来自 AI 公司的数据爬虫程序。
维基百科的服务器架构原本是为人类用户设计的分布式系统,在全球设有多个区域数据中心(欧洲、亚洲、南美等)和一个核心数据中心(美国弗吉尼亚州阿什本)。热门词条会被从核心数据中心缓存到区域数据中心,而访问较少的冷门词条则被存储在美国的核心数据中心。这种设计使得高频查询走“廉价通道”,低频查询走“高价通道”,既提高了用户体验,又降低了运营成本。然而,AI 爬虫的行为模式彻底打破了这一精巧的平衡。它们不分冷热,对所有内容一视同仁地抓取,导致 65% 的高成本流量都来自这些不知疲倦的数字劳工。

面对每年 300 万美元的服务器托管成本,以及 AI 爬虫带来的不成比例的资源消耗,维基媒体基金会最终选择了“打不过就加入”的策略。他们不仅提供了原始数据,还贴心地将其转化为 JSON 格式。各位开发者可能都知道,JSON 是一种机器友好,但对人类不友好格式,维基百科的打包 JSON 数据包含研究摘要、简短描述、图像链接、信息框数据和文章章节,但剔除了参考文件和音频等非书面元素。这种结构化处理显著降低了 AI 公司的数据处理成本,同时也将爬虫流量从维基百科的主服务器上分流出去。用一位观察者的话说,“这就像是为了保护老巢不被冲垮,维基给狼群做了一盘美味的肉,扔在了别的地方”。
AI爬虫的技术狂欢与法律灰色地带
AI 爬虫对维基百科的“狂啃”并非个例,而是生成式 AI 爆发式增长背景下的一个缩影。从内容平台到开源项目,从个人博客到官媒网站,几乎没有一个网络信息源能够逃脱 AI 公司的数据饥渴。ifixit 老板曾在社交媒体上吐槽 Anthropic 公司的 Claude 爬虫一天内访问其网站达 100 万次。Reddit 与微软因数据抓取问题爆发过长达数月的攻防战。而《纽约时报》更是直接将 OpenAI 告上法庭,指控其未经许可使用文章训练 AI 模型。
这些案例折射出一个根本性问题:在现行法律框架下,AI 爬虫究竟处于怎样的合规状态?从技术角度看,爬虫是通过程序模拟人类上网行为,高效抓取目标信息的工具,其本身是中性的。问题的关键在于应用方式和目的。维基百科采用知识共享署名-相同方式共享(CC BY-SA)许可协议,原则上允许任何人在遵守署名要求的前提下自由使用内容,包括商业用途。这使得 AI 公司能够以“合法合规”为由大规模抓取数据,只要他们满足基本的署名要求。
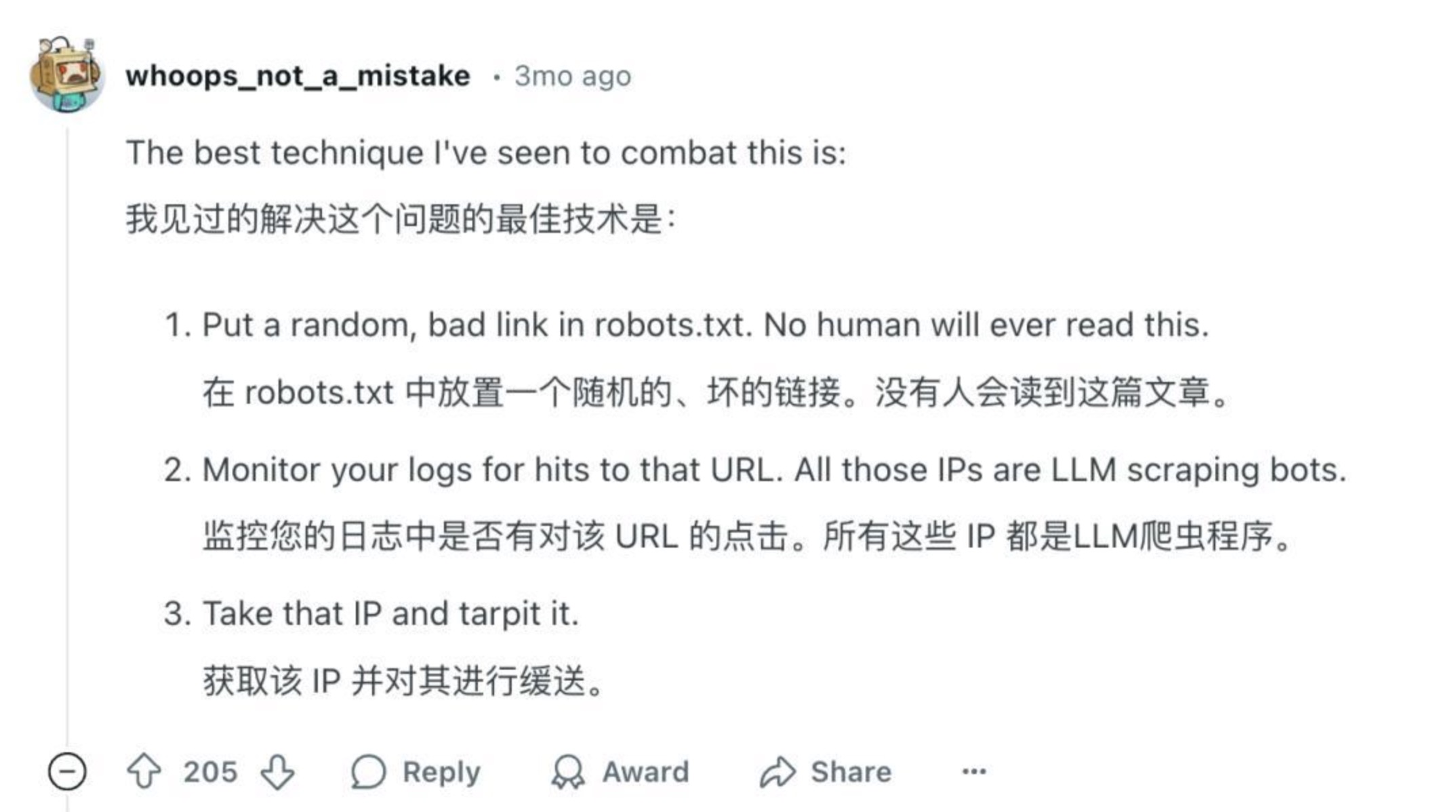
然而,合规性的边界正在变得模糊。传统的“君子协议” robots.txt(机器人排除协议)已经形同虚设。该协议允许网站明确告知爬虫哪些内容可以抓取,哪些应该回避。但在 AI 军备竞赛的压力下,“能爬尽爬”已成为行业潜规则。有报道显示,当 Reddit 用户在协议中明确禁止 OpenAI 爬虫后,后者只是简单修改了 user-agent(用户代理标识)便继续抓取。Perplexity AI 也被抓到直接无视 robots.txt 协议的行为。这种“你禁止鲁迅爬,我就用周树人的名义爬”的策略,使得技术防护措施越来越像一场猫鼠游戏。
法律专家指出,判断爬虫合法性的关键因素应包括:数据是否真正开放(公开 ≠ 开放)、获取手段是否具有侵入性、使用目的是否正当、是否造成实质性损害等。从民事法律角度看,突破网站反爬措施可能构成侵权。从刑事法律角度看,故意避开或突破技术屏障可能触犯非法侵入计算机信息系统罪、非法获取计算机信息系统数据罪等罪名。然而,这些法律条款在面对 AI 训练数据抓取这一新兴领域时,仍存在大量解释空间和适用争议。
自由与代价的两难
维基百科的“投降”深刻揭示了知识共享理念在 AI 时代面临的悖论。作为人类历史上最成功的协作项目之一,维基百科始终秉持“让知识自由获取和共享”的核心价值观。其运营模式依赖于全球志愿者的无偿贡献和用户的小额捐赠,而非广告或数据变现。这种非营利、开放的特性使其成为互联网上最后的“乌托邦”之一。
然而,正是这种开放性使其成为 AI 公司最理想的数据矿场。与《纽约时报》等商业媒体不同,维基媒体基金会既无法像 Reddit 那样向 AI 公司收取数据使用费(因为其非营利性质),也难以通过法律手段有效遏制爬虫行为(因为其开放的许可协议)。当 AI 公司利用这些免费资源训练出估值数百亿美元的模型时,维基百科却要为他们造成的服务器负担买单。
更深层次的问题在于,大规模 AI 爬虫正在改变知识共享生态的平衡。维基百科创始人吉米·威尔士曾设想的是一个“人人可编辑,人人可免费使用”的知识网络,但现实是,AI 公司既不是传统意义上的“人人”,其使用方式也远超当初的想象。当 AI 模型能够消化整个维基百科并生成看似权威的答案时,普通用户访问原始条目的需求可能会减少,进而影响维基百科的流量和捐赠收入。这种“被工具反噬”的风险使得一些观察者担忧,开放知识生态可能最终会沦为 AI 训练的养料,而非持续生长的有机体。
技术防御的军备竞赛与创新突围
面对 AI 爬虫的围剿,各类网站并非坐以待毙,而是发展出了一系列日益精巧的防御技术,形成了一场名副其实的网络安全军备竞赛。在 robots.txt 失效后,开发者们尝试了各种创新方法。有的在协议中设置“坏死链接”,只有爬虫才会点击的陷阱。有的利用 Web 应用防火墙 (WAF) 通过 IP 地址、请求模式和行为分析来识别恶意爬虫。更极端的如 Cloudflare 推出“错饭”技术,检测到恶意爬虫后不是阻止而是引导其进入一个充满无关信息的迷宫。
2025 年初问世的“Nepenthes 猪笼草”工具将这种思路推向极致。如同食虫植物猪笼草一样,该工具将 AI 爬虫困在没有出口链接的“无限迷宫”静态文件中,同时不断向其投喂“马尔可夫乱语”,他是由算法生成的毫无意义的文本组合,目的就是为了污染 AI 的训练数据。开发者声称,这项技术能让爬虫“吃下数字毒药”,目前只有 OpenAI 的爬虫能够逃脱。这种带有几分黑色幽默色彩的技术反击,反映了内容创作者在面对数据掠夺时的无奈与愤怒。
与此同时,一些商业平台选择了不同的道路。Reddit 和 Twitter 推出了面向 AI 公司的收费 API 计划,按数据使用量收费;《纽约时报》等传统媒体则诉诸法律武器,试图通过版权诉讼确立新的行业规则。这些尝试虽然方向不同,但都指向同一个目标:在 AI 时代重新确立内容的价值链和分配机制。相比之下,维基百科的 Kaggle 数据集策略可谓独辟蹊径。通过提供机器友好的数据包,既满足了 AI 公司的需求,又保护了主站的运营稳定性,不失为一种务实的选择。
未来之路:重构数字时代的“社会契约”
维基百科与 AI 爬虫的这场遭遇战,远不止是一个技术或法律问题,它迫使整个社会重新思考数字时代的知识生产、传播和使用规则。随着生成式 AI 逐渐成为信息基础设施的一部分,我们需要在技术狂热之外建立更健全的治理框架,平衡创新激励与公平补偿、开放共享与可持续发展之间的关系。
一种可能的解决方案是建立“数据信托”机制,作为内容创作者与 AI 公司之间的中介。在这种模式下,维基百科等平台可以通过信托机构授权数据使用,并获取适当补偿用于维持运营,而不违背其非营利原则。类似 Creative Commons(知识共享组织)已经推出“CC+AI”倡议,探索如何使开放许可协议适应 AI 时代的新挑战。
法律层面也亟需更新。欧盟《人工智能法案》和美国的多项立法提案已开始关注训练数据的透明性与合法性要求。未来可能会形成类似音乐版权集体管理组织的机制,AI 公司通过缴纳年费获取数据使用权,费用再根据使用情况分配给内容提供方。这种方案既能保障 AI 发展的数据需求,又能确保知识生态的可持续性。
技术解决方案同样值得期待。区块链技术可能实现数据使用的精确追踪。差分隐私和联合学习等新兴技术可以让 AI 模型从数据中学习而不需要直接复制原始内容。“数据尊严”概念倡导下,用户和创作者可能获得对其数字足迹的更大控制权。这些创新或许能在不牺牲开放性的前提下,建立更公平的知识价值循环。
结语:在颠覆中寻找平衡
维基百科向 AI 爬虫的“投降”,表面上是一个非营利组织面对技术冲击的无奈妥协,深层则是数字文明演进过程中的一个关键节点。这场风波暴露出当前知识生态的脆弱性,也预示着一个更根本的转变。当 AI 成为知识的主要消费者和生产者,我们如何重新定义创造者、使用者和技术之间的关系?
维基百科的选择不是对抗而是适应,不是封闭而是更聪明的开放,或许为我们指明了一条中间道路。在技术颠覆成为常态的时代,固守旧规则可能导致被边缘化,而全盘屈服又可能失去自主性。真正的智慧在于像维基百科那样,在坚守核心使命(知识自由)的同时灵活调整策略,通过创新参与规则的重塑而非被动接受他人的规则。
未来几年,随着 AI 技术进一步渗透到知识生产的各个环节,类似的冲突与调适将在更多领域上演。维基百科的故事只是一个开始,它的真正意义不在于谁输谁赢,而在于提醒我们,在技术狂飙突进的时代,更需要保持对人类价值与生态平衡的关切。毕竟,知识的终极目的不是训练更强大的 AI,而是滋养更明智的人类社会。













